Affordance Agent Harness: Verification-Gated Skill Orchestration
*Equal Contribution, †Corresponding Author
Abstract
Affordance grounding requires identifying where and how an agent should interact in open-world scenes, where actionable regions are often small, occluded, reflective, and visually ambiguous. Recent systems therefore combine multiple skills (e.g., detection, segmentation, interaction-imagination), yet most orchestrate them with fixed pipelines that are poorly matched to per-instance difficulty, offer limited targeted recovery from intermediate errors, and fail to amortize experience over recurring objects. We observe that many failures stem not from the lack of stronger models but from the lack of a system-level ability to actively acquire and validate evidence under bounded inference cost, where "verification" must rely on relative signals rather than ground-truth labels at test time. To this end, we propose Affordance Agent Harness, a closed-loop runtime that unifies heterogeneous skills with an evidence store and cost control, retrieves episodic memories to provide priors for recurring categories, and employs a Router to adaptively select and parameterize skills. Crucially, an affordance-specific Verifier gates commitments using self-consistency, cross-scale stability, and evidence sufficiency, triggering targeted retries when needed before a final judge fuses accumulated evidence and trajectories into the prediction. Experiments on multiple affordance benchmarks and difficulty-controlled subsets demonstrate a superior accuracy–cost Pareto frontier over fixed-pipeline baselines, improving grounding quality while reducing average skill calls and latency.
Motivation
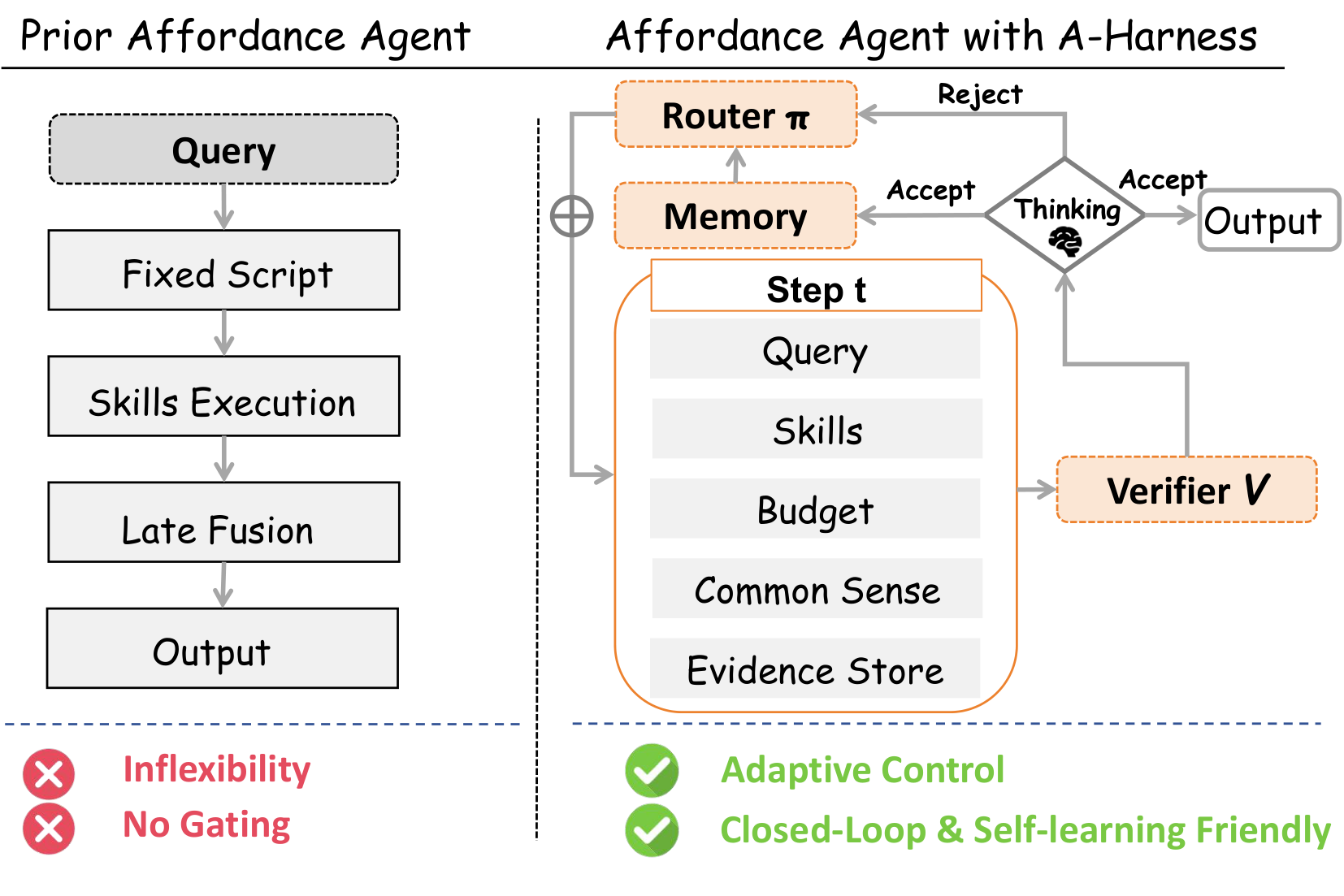
Affordance grounding remains brittle when decisions must be geometry-aware and evidence must be aggregated coherently across heterogeneous cues and tools. Existing agent systems exhibit three limitations: (1) Fixed Execution: they execute skills in a predetermined order regardless of input complexity; (2) Lack of Closed-loop Correction: they lack a mechanism to diagnose failure sources and re-invoke responsible skills when intermediate outputs conflict; (3) No Persistent Experience: recurring objects are re-solved from scratch each time.
We reframes affordance grounding as a budgeted, evidence-seeking decision process, where tool usage is a per-instance policy rather than a static script. We rely on three families of relative signals: (i) cross-tool consistency, (ii) cross-scale stability, and (iii) evidence sufficiency.
Methodology
If the PDF is not displaying, you can click here to view it in a new tab.
A-Harness consists of four key components:
- Evidence Store with Provenance: Accumulates heterogeneous skill outputs (boxes, masks, text) tagged with their source and zoom level to enable cross-skill agreement checks.
- Two-Tier Memory: A Common-sense Bank for stable priors of frequent objects and a Test-time Episodic Bank that accumulates verifier-accepted successful trajectories for online adaptation.
- Budget-Aware Router: Selects the next skill and its parameters by choosing the action most likely to resolve current uncertainty per unit cost (benefit-cost ratio).
- Verifier: Sidesteps the absence of ground truth by using relative diagnostics (consistency, stability, sufficiency) to gate commitments and trigger targeted retries.
Quantitative Results
Results on ReasonAff & UMD
| Model | ReasonAff (gIoU) | ReasonAff (cIoU) | UMD (gIoU) | UMD (cIoU) |
|---|---|---|---|---|
| VLPart | 4.21 | 3.88 | -- | -- |
| OVSeg | 16.52 | 10.59 | -- | -- |
| SAN | 10.21 | 13.45 | -- | -- |
| LISA-7B | 38.17 | 40.58 | 41.90 | 41.23 |
| SAM4MLLM | 45.51 | 33.64 | 12.40 | 8.41 |
| AffordanceLLM | 48.49 | 38.61 | 43.11 | 38.97 |
| InternVL3-8B/7B | 31.79 | 24.68 | 30.46 | 28.73 |
| Qwen2.5VL-7B | 25.18 | 20.54 | 33.21 | 29.83 |
| AffordanceVLM | 30.50 | 25.54 | 25.41 | 17.96 |
| Seg-Zero | 59.26 | 48.03 | 44.26 | 39.30 |
| Vision Reasoner | 63.04 | 52.70 | 44.00 | 39.71 |
| Affordance-R1 | 67.41 | 62.72 | 49.85 | 42.24 |
| Full Fixed Skill Chain | 55.05 | 49.57 | 50.19 | 49.24 |
| A-Harness (Claude-Opus) | 69.68 | 70.88 | 54.94 | 55.04 |
| A-Harness (Qwen-3.5) | 58.51 | 49.47 | 57.61 | 53.39 |
Results on RAGNet (3DOI & HANDAL)
| Method | 3DOI (gIoU) | 3DOI (cIoU) | HANDAL-E (gIoU) | HANDAL-H (gIoU) |
|---|---|---|---|---|
| G-DINO | 4.1 | 3.9 | 3.6 | 3.4 |
| LISA | 12.3 | 8.1 | 15.5 | 12.3 |
| GLaMM | 4.4 | 2.9 | 4.7 | 5.0 |
| Vision-Reasoner | 39.6 | 30.3 | 29.6 | 27.7 |
| Affordance-R1 | 39.0 | 33.4 | 43.1 | 40.7 |
| AffordanceVLM | 38.1 | 39.4 | 58.3 | 58.2 |
| A-Harness (w/o M-CS) | 56.5 | 47.2 | 58.4 | 55.3 |
| A-Harness (Full) | 65.6 | 53.7 | 63.5 | 62.8 |